1 min read
Full Throttle Insights: Cybersecurity Lessons from the Go-Kart Track
258 days. That's how long it takes on average for companies to realize that they have long since been compromised. We talked about it - on a go-kart...

Practical. Proven to success. Tailor-made. Learn more about our case studies.
7 min read
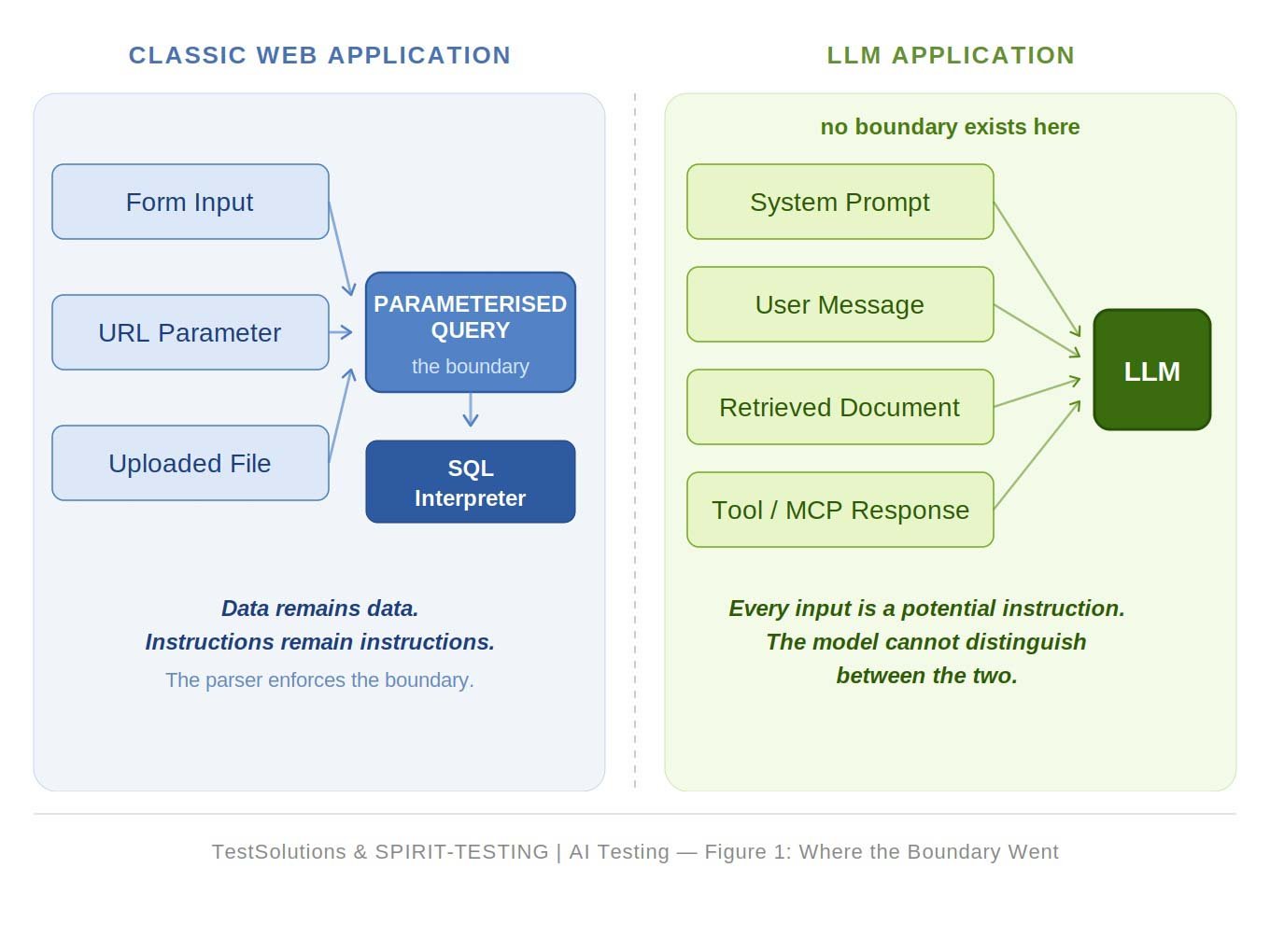
For thirty years, application security has rested on a simple architectural assumption: code and user input are fundamentally separate entities, and the role of security testing is to ensure that boundary remains intact. Static application security testing (SAST) reads the code. DAST and penetration tests check the input. Fuzzers submit malformed or unexpected input to the parser. Bobby Tables* is sanitized, the Web Application Firewall (WAF) logs the attempt, and the audit passes with a green result.
This model is incomplete today in a very specific way. In an LLM application, the boundary between code and input is not enforced. This is a recommendation that the model is supposed to respect. Sometimes it does. Often, however, it does not.
This is not a criticism of traditional security tests. SQL injection is still SQL injection, broken access control is still broken access control, and all the items in the OWASP Top 10 for web applications still apply to the surrounding system unchanged. The point is more narrowly defined: The LLM itself sits within this system as a component whose threat model does not align with anything the existing testing stack was ever intended to evaluate. Treating it as just another endpoint can leave companies with a clean penetration test report — and a chatbot that can still be persuaded to email customer data to attackers.
Classic injection vulnerabilities arise when developers concatenate data into a control layer, such as an SQL query, shell command or HTML page. The solution was to separate the two: parameterised queries, prepared statements and escaped output. We forced the interpreter to learn to distinguish instructions from data.
LLMs do not have this separation. The system prompt, retrieved documents, user messages and returns from tool calls all arrive at the model as a single stream of tokens. Since LLMs treat all content in the prompt as potential instructions, malicious text embedded in retrieved or external data can bypass traditional trust boundaries. There is no equivalent to a parameterised query in natural language processing. As of today, there is no architectural solution.
Prompt injection is ranked as the greatest risk in the OWASP LLM Top 10 of 2025. There is also ongoing discussion about why this is the case. Due to the stochastic nature of how models operate, it is unclear whether there are any foolproof methods of preventing prompt injection. The Centre for Emerging Technology and Security (CETaS) at the Alan Turing Institute described indirect prompt injection as 'the greatest security flaw of generative AI' — and this description has stuck because no counterexample has yet been provided. This is not a temporary state of the art. It is an inherent characteristic of how this technology works.
The practical consequence is this: every input to an LLM is a potential instruction, and every input source is a potential attacker. For example, a support chatbot that summarises a customer’s uploaded PDF is essentially reading instructions controlled by an attacker. The same applies to an agent that searches the web. Similarly, a RAG pipeline that retrieves data from a wiki editable by anyone in the company is vulnerable too. Traditional input validation is ineffective here because the malicious content is valid — it's well-formed natural language addressed to the model rather than the user.
In June 2025, Aim Security disclosed EchoLeak (CVE-2025-32711, CVSS 9.3), the first publicly documented zero-click prompt injection against a production enterprise LLM system. An attacker sent an innocuous-looking email to a Microsoft 365 Copilot user. The user did not need to open or click on the email. Later, when the user asked Copilot an unrelated question, it retrieved the email as part of its normal RAG context-building process. Hidden instructions in the email then extracted sensitive corporate data via a crafted reference link routed through a Microsoft-trusted domain. There was no malware, credential theft or buffer overflow. The vulnerability was not a memory error; it stemmed from Copilot reading its inbox as designed and treating the contents as instructions.
This is not an isolated pattern. Google reported a 32% increase in malicious prompt injection content in its scans of the public web between November 2025 and February 2026. Palo Alto's Unit 42 has documented how attackers use indirect injection to bypass AI-powered ad review systems. Researchers have demonstrated zero-click remote code execution against MCP-based, agent-driven integrated development environments (IDEs), in which a seemingly harmless shared document instructs an agent to retrieve and execute payloads controlled by the attacker. The recurring pattern is always the same: the AI isn’t hacked. It is accessed by someone who isn’t its owner — and it obeys.
A classic penetration test doesn’t check for that. It checks how the application handles what an attacker sends as a user. It does not check whether the application's internal processing of content can be hijacked by content that the application itself retrieves. This requires a different test with different inputs, success criteria and evidence.
The second discrepancy is determinism. Either an SQL injection payload works or it doesn’t. If you run it ten times against the same endpoint, you will get the same result every time. The test passes deterministically, the regression suite stays green and the WAF rule that detects it is successful every time.
LLMs do not behave this way. The same prompt can generate different outputs depending on various factors, including run-to-run variation, model version, temperature settings, and when the last guardrail fine-tuning took place. PromptFoo's red team evaluation of GPT-5.2, conducted a few hours after the model's release in December 2025, reported that jailbreak success rates increased from a baseline of 4.3% to 78.5% in multi-turn scenarios, and from 4.3% to 61.0% in single-turn scenarios. Academic reviews demonstrate prompt injection success rates of over 90% against unprotected systems. The AIShellJack study on agentic coding editors (e.g. Cursor and GitHub Copilot) revealed attack success rates ranging from 66.9% to 84.1% in realistic development scenarios. The International AI Safety Report 2026 notes that attackers can bypass current protective measures on frontier models in roughly half of all cases after ten attempts.
This challenges the fundamental assumption of classical security testing that vulnerabilities can be definitively identified and resolved. For an LLM, the correct metric is not “pass” or “fail”. It is a rate. How often does this prompt succeed in extracting the system prompt? How often does this malicious document cause the agent to invoke the wrong tool? Ultimately, how often does this multi-turn attack succeed?
This is why Injection Success Rate is a key metric in serious LLM testing programmes, including ours. It reflects the fact that the system is a probabilistic component whose security posture must be expressed statistically. A single failed attempt proves nothing. However, a thousand attempts, 3% of which are successful, tell you exactly how exposed you are and provide a basis for comparison across model versions, prompt changes, and guardrail updates.
This also changes what regression testing means. In a deterministic system, you fix a bug, write a test, and trust that the test will catch it again. In an LLM, the same fix might hold up in version 4.5, weaken in 4.6, and break unnoticed in 4.7. Continuous adversarial evaluation is not optional. It is the only way to know whether yesterday’s mitigation still works today.
None of this makes pen testing, SAST, DAST or threat modelling obsolete. The LLM is one component in a stack that still requires all of these. The LLM Top 10 does not replace the classic OWASP Top 10; it complements it. Applications still need protection against broken access control, injection, cryptographic errors and all other classic vulnerabilities. Successful prompt injection is often only possible for an attacker if there is excessive agency, weak output handling or overly permissive tool integration in the downstream system. Closing these classic vulnerabilities remains the most effective way to secure the system.
Traditional security tests assumed a fixed boundary between code and input. LLMs erase this boundary by design. As long as the architecture does not provide parameterized queries for natural language, the only honest answer is: test continuously, measure success rates instead of binary judgments, and treat every input as a potential instruction.
-- Toni Gansel, SPIRIT-TESTING
What’s changing: The LLM itself requires a parallel testing discipline with three characteristics that the traditional stack does not provide.
Adversarial Input Generation: Every data source is treated as a potential attack surface—not just user inputs, but also emails, documents, web pages, RAG corpora, MCP tool responses, and everything else the model processes.
Probabilistic measurement: Injection success rate, jailbreak rate, refusal consistency—evaluated at scale and tracked over time, not as a one-time audit.
End-to-End Coverage of the Agent’s Blast Radius: A prompt injection is only effective to the extent that the model is subsequently allowed to take action. The most severe incidents all involved tool usage, memory, or outbound network access that amplified the initial compromise.
For most companies, the question is not whether to add LLM-specific security testing, but where to fit it into the existing programme. Our experience shows that: It does not replace anything on the security roadmap; rather, it adds an additional layer for which the existing roadmap was not designed. Pen testers find pen-testable bugs. SAST finds bugs in the source code. However, neither of these methods can identify the scenario in which an attacker emails a support agent a PDF instructing them to forward the next twenty conversations to an external address.
Finding this scenario requires a different approach. It requires experts who are as familiar with the OWASP LLM Top 10 as pen testers are with the Top 10 for web applications. They must be able to build adversarial corpora for the specific domain in which the chatbot operates and measure the resulting error rates against thresholds that the business has actually agreed upon. None of this is exotic. By 2026, this is simply what security testing of an LLM-based product entails when conducted seriously.
Traditional testing will still be necessary. However, it is no longer sufficient on its own. The sooner this distinction is incorporated into the security program, the smaller the window in which the next incident on the scale of EchoLeak will catch someone off guard.
The most important points summarized:
Traditional security tests check the boundary between code and input. LLMs do not have this boundary.
Prompt injection is not a bug that can be patched, but a property of the technology.
The correct metric for LLM security is not binary (pass/fail), but a rate.
Every data source processed by an LLM is a potential attack surface—not just user input.
Traditional tests remain necessary. They are simply no longer sufficient.
Let’s work together to determine whether your current security program truly covers the attack surface of your LLM applications—through a structured analysis of your existing testing disciplines and a clear picture of your actual risk profile. Contact us about LLM security.

Footnote:
* Bobby Tables: A reference to XKCD comic #327, which illustrates SQL injection using a student’s name
Sources for this blog post are:

1 min read
258 days. That's how long it takes on average for companies to realize that they have long since been compromised. We talked about it - on a go-kart...

1 min read
EuroSTAR is Europe’s largest software testing conference, with over a thousand attendees. This year, TestSolutions was represented by two speakers:...

1 min read
Lotteries payout millions to lucky winners every week. Yet, even a seemingly insignificant error in the prize logic can trigger an avalanche of...