 Anupam Krishnamurthy
Anupam Krishnamurthy
LLM Security: Why Traditional Security Testing Is Not Enough for AI Applications
For thirty years, application security has rested on a simple architectural assumption: code and user input are fundamentally separate entities, and...

Practical. Proven to success. Tailor-made. Learn more about our case studies.

EuroSTAR is Europe’s largest software testing conference, with over a thousand attendees. This year, TestSolutions was represented by two speakers: Florian Fieber, our Chief Process Officer, who is an experienced conference speaker; and Anupam Krishnamurthy, Head of AI Testing at TestSolutions GmbH, who wrote this article.
It was my first time at EuroSTAR, and I was genuinely impressed by the conference's scale and the quality of its speakers and attendees. The conference is held in a different European city each year. This year's edition took place in Oslo.
As expected, AI in software testing was the dominant theme this year, accounting for more than half of the sessions. Several sessions focused on the practical, hands-on application of AI in testing, covering topics such as agentic workflows, AI-driven test monitoring, multi-agent orchestration and the use of AI to support exploratory testing. Another cluster dealt specifically with testing AI itself, covering topics such as how to structurally test AI-based agents and which metrics are important for evaluating generative AI output. AI security was also covered, with talks on prompt injection and OWASP LLM risks. Notably, however, this was not uncritical AI enthusiasm; many talks explicitly questioned the hype, asking whether AI has actually delivered on its promises. This is all in close alignment with our own internal thinking and approach to AI at TestSolutions.
The remaining talks focused on traditional test automation techniques, emphasising the fundamentals. There were also talks on the human side of testing — sessions on critical thinking, psychology, leadership and communication outlined how humans will continue to be relevant in the era of AI-assisted software development. A handful of talks shared the experiences of quality transformation in large corporations, covering the milestones achieved, challenges overcome, and lessons learnt.
The first of the two TestSolutions presentations was prepared in collaboration with Susanne Kunkel from the Lufthansa Group’s Test Factory and delivered by Florian Fieber, Chief Process Officer at TestSolutions GmbH in Oslo. The presentation began with a description of the scale of the Lufthansa Group and TestSolutions and then walked the audience through the establishment of a global Test Factory. This Test Factory delivers consistent, high-quality testing services across a broad spectrum of projects and technologies—marking a shift from a fragmented and inefficient past to a harmonized and scalable present.
Rather than remaining abstract, the session grounded these building blocks in the areas on which the Test Factory focuses day to day: test data management, accessibility testing, scaled agile testing and, increasingly, AI-related testing. Most striking was how candid Florian and Susanne were about the more challenging aspects of their journey. Lufthansa's core business is flying planes, not writing software, so historically, IT and testing have been viewed internally as a cost centre rather than a source of value. Building a case for a dedicated Test Factory therefore meant going against the grain.
The Lufthansa Group operates in a complex international regulatory environment spanning several geographies. The need for autonomy and decentralisation had to be balanced with standardisation and economies of scale. The talk described how the Group’s sourcing requirements vary between internal and external experts, and further between onsite and offshore. The Test Factory currently employs more than 250 people, 84% of whom are based offshore, across eight business units. Real-life examples were provided for both waterfall and scaled Agile project delivery. A particularly notable result is that the Test Factory can now identify demand within a project and staff it with an offshore expert within one week.
I was particularly impressed — as were several others in the audience, who came up to us afterwards — by how Florian managed to convey so much valuable information on such a vast topic, piecing it together into a coherent narrative while staying within his allocated 30 minutes.

In my own presentation, I began with the story of the Tenerife airport disaster, in which two Boeing 747s collided on the runway at Los Rodeos Airport, claiming the lives of 583 people. The cause was a miscommunication between the control tower and the pilot of one of the aircraft, triggered by ambiguous natural language. Since our AI systems today communicate and act based on instructions in natural language, we need mechanisms to ensure that miscommunication does not lead to defects or bugs—or even to disasters with fatal consequences.
I then explained the core challenge of testing large language models automatically. As their outputs are probabilistic and expressed in natural language, the same input can produce different outputs, some of which may be correct but none of which can be predicted in advance. We need to transition from automating static assertions to automating judgement calls. The industry standard for overcoming this challenge is to configure an additional LLM — an LLM-as-a-judge — to verify the output of the LLM being tested. However, the judge LLM must be aligned with a human domain expert for its evaluation to be accurate.
I gave a live demo to accompany the talk, in which I described the LLM-judge alignment process using the example of an airline customer service chatbot. This alignment is based on a set of ground truths, also known as a golden dataset, consisting of a series of questions and clear pass/fail criteria for evaluating each one. We explored how, while this process may appear straightforward, it can contain several pitfalls.
Once aligned, an LLM-judge can be used like a calibrated instrument to perform experiments that continuously improve the AI system. We can change one component of the system and use the LLM-judge to evaluate whether this has improved or deteriorated performance. It is at this point that the LLM-judge potentially upgrades from being merely an automated test oracle to becoming an instrument for continuous improvement.
My talk was very well received. In fact, it was voted by the audience as one of the two best talks of the event! I was asked several questions on stage, which led to inspiring conversations that continued long afterwards.

As we say in Germany: after the conference is before the conference. Florian Fieber and I are taking away many ideas and plenty of inspiration that we’ll continue to build on. On July 10, from 11:30 a.m. to 12:15 p.m., I’ll be presenting the next version of my talk on LinkedIn. This time, it will be in German under the title “Can You Trust Your AI Chatbot? With a Live Test Demo!”
If you missed my talk at EuroSTAR, or would like to see a new and improved version covering AI chatbot testing and LLM evaluation in greater depth, please feel free to join us there.
Interested in LLM testing for your organisation?
Interested in LLM testing for your organisation?
Would you like to explore how automated LLM testing and AI quality assurance could strengthen your software development process? Get in touch — we would be happy to share our experience.

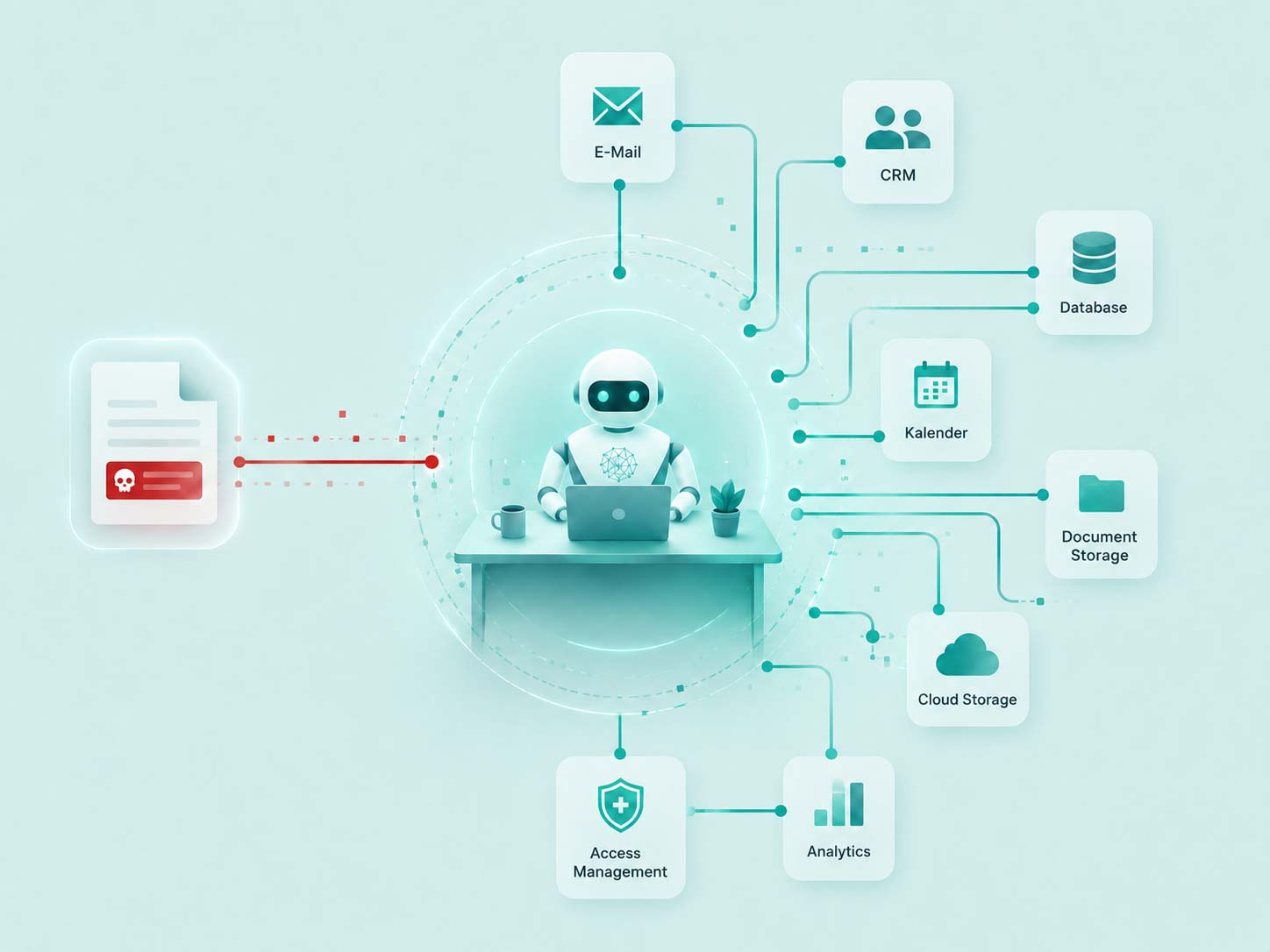
For thirty years, application security has rested on a simple architectural assumption: code and user input are fundamentally separate entities, and...

AI is also finding its way into AI-powered software testing. In regulated industries, the reaction to this is often mixed: interest on the one hand,...

TestSolutions is pleased to welcome Prof. Dr. Marco Barenkamp, LL.M. to its Advisory Board. With his deep expertise, entrepreneurial experience, and...